Simulating Earth
I was recently at a holiday get-together with family and, as often happens at such events, the conversation turned to politics—climate change and green energy policy specifically. One of the claims I heard that day was that climate forecasting models are not accurate. While that claim was not substantiated, I had always assumed that at least some climate models were accurate to a good degree and it got me thinking—climate models are software, and software is my career, I should probably get some first hand knowledge of what a climate model really looks like. After a little bit of research, I discovered a climate model called the Community Earth System Model (CESM). It seemed like good candidate for exploration since it is a top tier climate model, is fully open source, and is well-documented. In this article, I will provide my findings and thoughts on this climate model from the perspective of a software engineer (I’m not a climatologist) and whether public policy should be informed by such endeavors. I will be analyzing version 2.1.5 [3] which, at the time of this writing, is the latest production release and has been scientifically validated.
Funding and Management
A good place to start our exploration is by understanding who funds and oversees the CESM project.
CESM is developed by the National Center for Atmospheric Research (NCAR) [1]. NCAR is a federally funded research center that supports a wide range of atmospheric and Earth system science. NCAR is funded by the National Science Foundation (NSF) and managed by the University Corporation for Atmospheric Research (UCAR).
UCAR is a consortium of more than 100 North American universities and research institutions focused on Earth system science. The vast majority of its members are based in the United States. In summary, CESM is essentially a collaboration between the U.S. government and U.S. universities.
Architecture
CESM is a distributed discrete-time finite-volume geophysical simulation of Earth. It consists of 7 geophysical components (atmosphere, land, sea ice, ocean, land ice, river runoff, and ocean waves) and a coupler. The coupler, called CIME (pronounced “seam”), is responsible for initializing the scenario, coordinating the geophysical components, and managing the overall progression of simulation time. Each component operates in parallel with the others, managing its own local time and state. They periodically exchange information via MPI-based interfaces, with each component providing its contribution to the overall climate state and receiving updated data from the others.
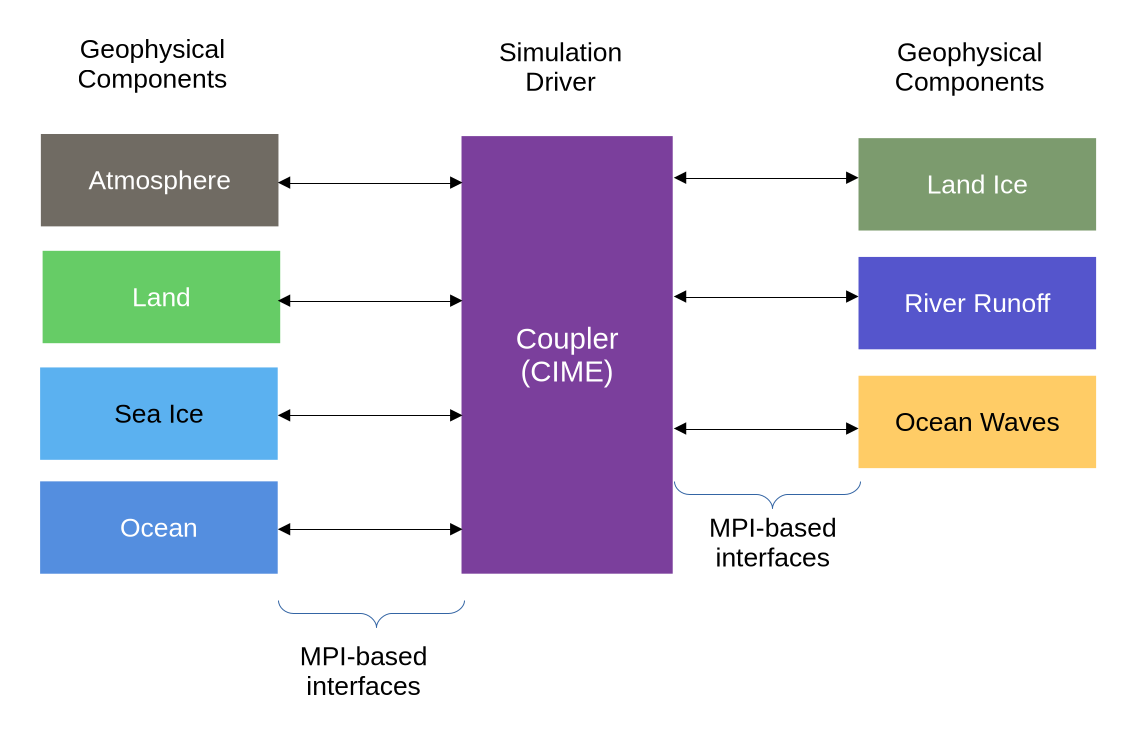
A CESM run at full resolution requires extensive computing resources. On NCAR’s Cheyenne supercomputer, CESM can simulate about four years per day at its highest-fidelity configuration. The modular architecture allows for flexibility in the run configuration to support development, testing, and validation of components individually without the need for long feedback cycles. “Data” versions of the components feed precomputed data to CIME, allowing a single active component to be exercised in a scientifically valid way. “Dead” versions of the components enable non-scientific technical testing of the CIME coupler without the cost of running the active components [2].
License, Literature, and Data
CESM is generally released under a permissive BSD-style license, which allows for broad reuse and modification. It also includes at least one component licensed under the GNU General Public License (GPL), which requires redistribution of any derived works under the same license.
In addition to the open-source code, many peer-reviewed journal articles are published in open access journals such as JAMES (Journal of Advances in Modeling Earth Systems). Supporting literature from NCAR and UCAR scientists—such as technical notes, reports, and presentations—is freely accessible through the OpenSky repository. CESM simulation data is also openly available for download from the CESM project website.
The commitment to open science—across software, literature, and data—is what makes larger technical engagement, including this article, possible. Openness greatly enhances credibility trust and not all climate models are as open as CESM.
Programming Languages
CESM, including CIME and all the standard components and tools, is primarily written in Fortran at approximately 1,300 KLOC (thousand lines of code)—so its a huge system. Python follows with 56 KLOC, then C at 50 KLOC, and Shell scripts with 17 KLOC.
Let me now take a brief excursion on Fortran. Back in 2004, my master’s independent study project analyzed the suitability of using the Java programming language for scientific programming. I was motivated at the time by witnessing some older engineers completely stagnate in their programming language knowledge and being oblivious to the benefits being offered by newer languages. Such engineers were stuck with the paradigm of Fortran 77 more than 25 years after its debut. They expressed strange thoughts like, for example, that using a DO loop instead of GO TO was being “modern”. As a young engineer, I knew that there was a new world of programming languages emerging. I felt sorry for the engineers stuck in that old Fortran mindset and wanted to put something substantial out there to help open their eyes.
I ran some experiments and determined that in cases where the program was IO-bound, there was no performance penalty to using Java over the older generation of programming languages and lots of benefits to be gained. In cases where the program was CPU-bound, there was a high performance penalty to be paid to use a VM-based language like Java and engineers were still better off using the older languages that compile to native machine code like C, C++, and Fortran. In the 20 years since, we have seen much adoption of more modern programming languages for scientific computing especially Python, but also Java and C# in some contexts with even newer alternatives like Rust and Go now emerging.
So, with CESM being written mostly in Fortran, one might wonder whether this reflects an outdated mindset. My assessment is that, no, that fact itself, does not reflect an outdated mindset for the following reasons.
-
CESM uses LAPACK heavily. LAPACK was written in Fortran in the 80s and has never had a full rewrite in a more modern language–and for good reason since it is a huge amount of very esoteric numerical linear algebra. LAPACK is either wrapped (as in LAPACKE) to be called from another language using C calling conventions or automatically translated from Fortran (as in CLAPACK). Wrapping is certainly a viable option if only a few functions here and there are being used, but the more that an application uses LAPACK, the more Fortran becomes a natural fit for it.
-
CESM is computationally and CPU-intensive with full runs potentially taking weeks to execute. So, close-to-the-machine languages like Fortran, C, C++, and Rust are the only viable options. Using languages for performance sensitive components like Python or Java would likely come at a huge cost in runtime.
-
Improvements in later versions of Fortran are being taken advantage of or at least available for use. The vast majority of code files utilize the free-form source format that was introduced with Fortran 90. Fortran features through Fortran 2008—such as simple object-orientation, and array index checking (in debug builds)—are generally being used to some extent.
Most of the Fortran code that I’ve browsed through seems reasonably easy to read at a superficial glance. That being said, it was not difficult to find some of the kind of horrifying code that many people have come to expect from Fortran, such as this example.
That example appears to be code that was generated by a script perhaps to unwind a loop for performance—an old optimization technique that is largely obsolete now given modern compiler optimizations. But there are no comments giving any idea where this came from or why they did this. Every project has some skeletons in the closet.
Realism of Results
Now the big question everyone probably wants to know is—do the results from CESM reflect reality or is this more like a glorified video game model?
For those wanting a deep dive into how CESM was validated, I recommend reading The Community Earth System Model Version 2 (CESM2) [4] in full. What follows is my summary and perspective on that work—from the vantage point of a software engineer (with no formal training in climatology) evaluating a scientific model.
CESM2, finalized in 2019, was validated through extensive comparisons of model output to independently curated datasets of real-world climate observations spanning the last 150 years. These comparisons were made across numerous metrics, over both time and space. Take something like average daily precipitation: the paper presents global heat maps showing both CESM’s output and the observational data at fine resolution. It also includes a third heat map showing the difference between model output and reality, revealing where biases are present.
These visualizations aren’t cherry-picked. The paper walks through this process for around 15 major metrics—things like surface air temperature, sea surface temperature, and sea ice extent. The result is a multidimensional validation that gives a strong overall sense of how well the model replicates Earth’s climate.
Crucially, they also include experiments that fail validation—scenarios where the model’s outputs diverge too much from known data. And that’s a good thing. As a hard-nosed engineer, I want to see a tests failing some of the time. If every simulation “passes,” you have to wonder whether your validation system is really doing its job. That’s clearly not the case here.
The paper also includes comparisons with CESM1, the earlier version of the model completed in 2013. I went in expecting CESM1 to seem primitive next to CESM2, but that wasn’t the case. While CESM2 brings real improvements in several areas, CESM1 was already producing impressively realistic climate simulations. CESM2’s gains, while meaningful, are often refinements rather than leaps.
In conclusion, CESM2 emerges as a thoroughly validated model that demonstrates strong alignment with historical climate data, while also exposing its own limitations quite transparently. It shows strong predictive power—and like any good software system, it has room to grow. I strongly believe that public policy makers should be heavily weighing the scientific results from mature and open climate models like CESM as long as that consideration is made with awareness of the limitations and uncertainties inherent in the modeling process.
Thoughts on the Future and Conclusions
Work on CESM should continue. While the overall trajectory of the climate system is well-established—demonstrated repeatedly by observational and modeling studies—there are still many more experiments to be run and much more to learn. It will be interesting to see what CESM3 brings.
I’d like to offer a few humble thoughts on potential future architectural directions. CESM was originally designed for an era in which supercomputers were essentially clusters of modestly spec’d Linux machines connected by a low-latency network such as InfiniBand. That remains largely true today. However, several technologies that have matured over the last couple of decades could significantly benefit climate models like CESM and merit evaluation.
GPUs offer the potential to accelerate computation by enabling finer-grained parallelism. Full high-fidelity runs can take substantial time to complete. Reducing these runtimes without sacrificing model fidelity could dramatically speed up both development cycles and the time to generate scientifically validated results. Rewriting key parts of the model to run on GPUs will likely be difficult, but the payoff could be substantial.
The Cloud, and particularly containerized workloads, opens new paths for reproducibility and accessibility. Currently, running CESM typically involves creating a custom configuration tailored to a particular supercomputer. Bit-for-bit reproducibility across systems is not currently attainable. Ideally, a scientifically validated configuration would be delivered as a containerized workload, runnable by anyone in the Cloud in a consistent and repeatable way. Cloud providers today offer low-latency networking options suitable for MPI workloads such as AWS’s Elastic Fabric Adapter [7] or Azure’s InfiniBand-enabled VMs [6]. Smaller organizations and research groups could get in on the game by acquiring a supercomputer on demand in the Cloud and tearing it down when runs are complete to minimize costs.
Overall, I am impressed by CESM’s high fidelity modeling, rigorous validation, and the openness of code and data. Like any big software project, it has its share of code cruft, but that doesn’t impeach the scientific validity of its results in any way. I look forward to the future evolution of CESM, the new scientific insights it will bring, and hopefully the emergence of a more cloud-friendly architecture.
References
- National Center for Atmospheric Research. Community Earth System Model (CESM) UCAR. https://www.cesm.ucar.edu/
- CESM Project. CESM2.1 Online Documentation NCAR. https://escomp.github.io/CESM/versions/cesm2.1/html
- CESM Project Developers. Community Earth System Model (CESM), version 2.1.5 GitHub. https://github.com/ESCOMP/CESM/tree/release-cesm2.1.5
- Danabasoglu, G., et al. (2020). The Community Earth System Model Version 2 (CESM2) Journal of Advances in Modeling Earth Systems. https://agupubs.onlinelibrary.wiley.com/doi/10.1029/2019ms001916
- Edwards, J., et al. (2021). Performance of the Community Earth System Model on Three Advanced Computing Architectures Earth and Space Science. https://agupubs.onlinelibrary.wiley.com/doi/full/10.1029/2020EA001296
- Microsoft. HB- and HC-series VMs for HPC Microsoft Learn. https://learn.microsoft.com/en-us/azure/virtual-machines/overview-hb-hc
- Amazon Web Services. Elastic Fabric Adapter AWS. https://aws.amazon.com/hpc/efa/
Acknowledgements
ChatGPT was used in the preparation of this article for light proofreading, stylistic suggestions, and formatting.